希尔排序
希尔排序 简介
希尔排序是插入排序的改进方法。它针对插入排序的改进思想有两点:
- 插入排序在对几乎排好序的序列进行操作时效率非常高,几乎接近线性。
- 插入排序对不理想的序列时,每次都要移动数据一位数据,这对M个子序列时需要进行M-1次操作。
如何取其长,补其短,便是希尔排序想要的。
希尔排序的思想是:重复对序列进行不同子序列的划分并实施插入排序,最后对整个序列进行插入排序。
子序列的划分使用步长来确定,如步长为m时,每隔m-1个位置划分成一个子序列。所以当步长为1时,该子序列包括了整个序列。
希尔排序如图所示:

在希尔排序中,划分的子序列中的元素个数是从少到多,因此可以有效避免一次移动数据位太多情况,并且少量的 元素个数使得插入排序有很高的效率。最后对整个序列进行插入排序时,因序列几乎有序,不会耗费太多的操作。但因为需要进行分组对子序列进行排序,该算法是不稳定的算法。
创作者的思路体现的非常明显:对每次操作几乎线性的效率使得算法总效率大大的提高。
希尔排序的空间复杂度很好计算,没有使用额外的空间所以是 O(1)
而时间复杂度的计算比较麻烦,它需要根据子序列如何划分即步长进行计算。不同划分方法,理论计算得到的希尔排序时间复杂度并不相同。这里给出常见的三种步长下的最差时间复杂度:
| 步长序列 | 最坏情况下的时间复杂度 |
|---|---|
| \(\frac{n}{2^i}\) | \(O(n^2)\) |
| \(2^i-1\) | O(\(n^{\frac{3}{2}}\)) |
| \(2^i3^j\) | O(\(nlog^2n\)) |
这里对步长为\(\frac{n}{2^i}\) 时最差时间复杂度是O(\(n^2\))进行证明:
证明
假设序列长度为N,每次步长为\(\frac{N}{2^i}\)
对于每次分组存在着\(2^i\)个子序列,每个子序列中的元素个数为:\(\frac{N}{2^i}+j\) (j = 0,1)
因j是常数,在计算时间复杂度时刻意地进行忽略。于是在每次分组中,对于每个子序列的最差时间复杂度为\((\frac{N}{2^i})^2\)
于是在一次分组中,总的最差时间复杂度为:子序列的个数 X 子序列的最差时间复杂度 = \(2^i\) * \((\frac{N}{2^i})^2\) = \(\frac{N^2}{2^i}\)
步长从\(\frac{N}{2}\) 开始,直到1时介绍,因此总共进行了\(\hat{i} = logN\) 次分组。这里的\(\hat{i}\) 通过上式可能为无理数,但并不影响最后时间复杂度的计算。
通过对每次分组的时间复杂度进行求和,得到步长为\(\frac{N}{2^i}\)总的最差时间复杂度为:
\[\sum_{i=0}^{logN}\frac{N^2}{2^i} = N^2+\frac{N^2}{2}+\frac{N^2}{4}+....+1=\frac{N^2(1-\frac{1}{2}^{logN})}{\frac{1}{2}}=2N^2(1-\frac{1}{N})\]最后得到最差时间复杂度为:\(O(N^2)\)
归并排序
归并排序 简介
归并排序(Merge sort) 采用了分治法(Divde and Conquer),记得看麻省算法课时这是给我印象最深的一个算法。分治法,分而治之,将一个复杂的问题分成多个相同或是相似的子问题,直到最后的子问题可以简单直接的求解,原问题的解即是子问题解的合并。它是一个递归算法,每次递归可以总结为三个步骤:
- 分解:将原问题分解为若干个更小规模,相对独立且与原问题相同的子问题。
- 解决:若子问题规模小到一定程度时,直接求解。否则,递归地解决各子问题
- 合并:子问题的解合并为原问题的解
在归并排序中同样遵守这三个步骤:
- 分解:将序列一分为二,对每个子序列继续套用归并排序算法
- 解决:若序列元素个数为2,则进行比较两元素大小并进行排序。否则,继续分解。
- 合并:对临近两两子序列的元素进行比较,并重新组成一个新的有序序列。
图中所示的是至下而上的归并排序图:

归并排序的时间复杂度为:O(\(nlog_{2}n\))
空间复杂度为:O(n)
接下来进行证明:
证明
假定存在一个元素个数为n的序列 T(n) , 对其进行归并排序,分解的流程图如图所示:
这里直到将其分解为1个元素,共需要分解\(log_{2}n\)次,也意味着这颗树的深度为 \(log_{2}n\) 。而每一层每次分解和重新合并需要的总时间复杂度为:\(k * \frac{n}{k} = n\)
于是总的时间复杂度为:O(\(nlog_{2}n\))
使用递归算法的时间复杂度公式同样可以进行推导:\(T(n)=aT(\frac{n}{b})+f(n)\)
\[T(n) = 2T(\frac{n}{2})+n\] \[T(n) = 2(2T(\frac{n}{4})+\frac{n}{2})+n = 4T(\frac{n}{4})+2n\]…..
且\(T(1)=0\)
所以:\(T(n)=nT(1)+(log_{2}(n))*n = O(n*log_{2}(n))\)
空间复杂度:直接考虑最后一次合并,需要额外长度为n的空间来合并两个\(\frac{n}{2}\)的序列。所以时间复杂度为O(n)
归并排序算法
def conquer_merge_sort(unsorted_list):
# 当子序列只有一个元素时
if(len(unsorted_list)<2):
return unsorted_list
else:
# 对序列进行分解
middle = int(len(unsorted_list)/2)
left,right = unsorted_list[0:middle],unsorted_list[middle:]
return merge(conquer_merge_sort(left),conquer_merge_sort(right))
# 合并
def merge(left,right):
result=[]
while left and right:
if(left[0]<right[0]):
result.append(left.pop(0))
else:
result.append(right.pop(0))
while left:
result.append(left.pop(0))
while right:
result.append(right.pop(0))
return result
快速排序
快速排序 简介
快速排序同样运用了分而治之的思想,它的算法步骤如下:
- 从序列中挑出一个元素,称为“基准”(pivot)
- 对序列进行排序,将大于“基准”值的数放到基准值右边,小于“基准”值的数放左边,排序完成后,基准处在序列中间的位置。
- 递归地,对每个基准值两边的两个子序列执行2中的操作。
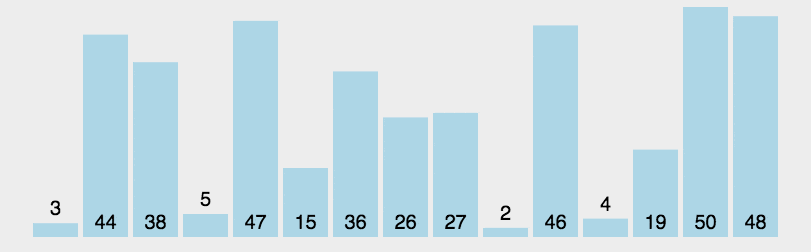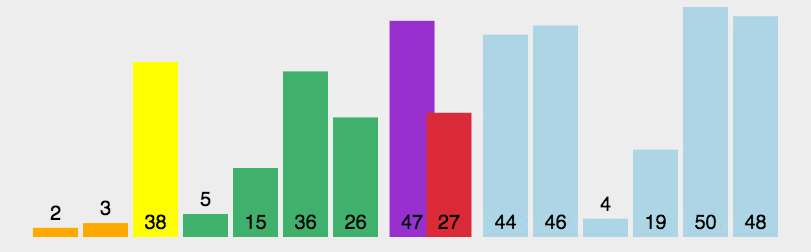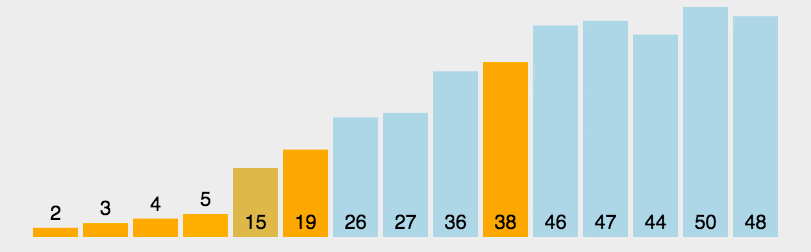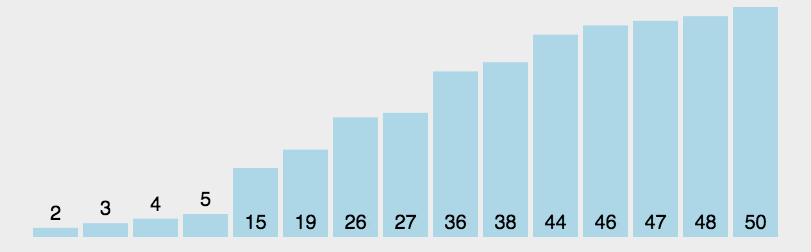
快速排序的时间复杂度为O(\(nlog_{2} n\)),最坏情况为\(O(n^{2})\) 。与归并排序相比,它的隐含的常数因子很小,同时最坏情况不易出现,所以,对大多数顺序较弱的随机序列相比,快速排序总是由于归并排序。
快速排序代码
def quickSort(unsorted_list, left=None, right=None):
left = 0 if not isinstance(left,(int, float)) else left
right = len(unsorted_list)-1 if not isinstance(right,(int, float)) else right
if left < right:
partitionIndex = partition(unsorted_list, left, right)
quickSort(unsorted_list, left, partitionIndex-1)
quickSort(unsorted_list, partitionIndex+1, right)
return unsorted_list
def partition(unsorted_list, left, right):
pivot = left
index = pivot+1
i = index
while i <= right:
if unsorted_list[i] < unsorted_list[pivot]:
swap(unsorted_list, i, index)
index+=1
i+=1
swap(unsorted_list,pivot,index-1)
return index-1
def swap(unsorted_list, i, j):
unsorted_list[i], unsorted_list[j] = unsorted_list[j], unsorted_list[i]